How does Hadoop Switch Replica When Datanode Gets Crashed

In our last article, we talked about that companies need data to run and grow their business. We also did a complete case study on how ecommerce platforms are using hadoop to work with bigdata. In this article, we are going to show a demonstration of how hadoop stores the data in master-slave architecture and what happens if the datanode in which data is stored gets crashed and someone was reading data from that node on the same instant.
How Hadoop Stores Data?
When any client or datanode uploads any file on hadoop cluster, it creates 3 replicas of the data as a backup. The backup can be used whenever one node gets crashed where data was stored, we can still read the data from other replicas of it. Now the question arises what will happen if someone was viewing an image or video or text file stored on the hadoop cluster which distributes data to different name nodes (distributed storage cluster) and the node from which the data was being read, if it gets crashed, then some part of image won't be visible? or the video won't play at some points? or text file won't show some lines? If that is the case then Facebook, Instagram etc. which has a the real big data then these companies would have failed badly. So, what happens if the node gets crashed? How is the data still being read without refresh? In this article, we are going to see an easy demonstration of what happens at backend in these kinds of cases.
What We Want to Achieve?
- Setup a hadoop cluster with one Namenode (Master) and 4 Datanodes (Slave) and one Client Node (To upload data)
- Upload a file through client to Name node
- Check which data node the master chooses to store the file
- Once uploaded, try to read the file through client using the cat command and while master is trying to access the file from datanode where the file is stored, delete that datanode or crash it and see with the help of replicated storage how master retrieves the file and present it to the client.
The Actual Demonstration
Our team of 4 members together created a hadoop cluster in which one was master node and others contributed as data nodes. For better observation, upload a large file on hadoop cluster. One of the clients uploaded a file on the hadoop cluster using the command:
hadoop fs -put
For example:
hadoop fs -put pawan.txt /
Our Team Working Together:

Now one of the team members can start reading the file either from the command line or from the GUI (Graphical User interface). To read from GUI, browse port no. 50070 on web browser with any one of the IP address of nodes in the hadoop cluster. To read from command line, use the command:
hadoop fs -cat
For example:
hadoop fs -cat /pawan.txt
Now the thing is, we have to observe from which node or replica the data is being read. For this, we can use tcpdump. Tcpdump is a program to monitor and analyse data packets over the network. Now hadoop communicates at port 50010 with the client or data nodes by default. So, we will start monitoring incoming traffic at port 50010 of all the instances with the help of tcpdump using the command:
tcpdump -i
For example:
tcpdump -i eth0 tcp port 50010 -n
You can check your network interface card name using ifconfig command in Linux. You can use either -n (for just data packets) or -x (for data in hexadecimal format) at the end to visualise the data.
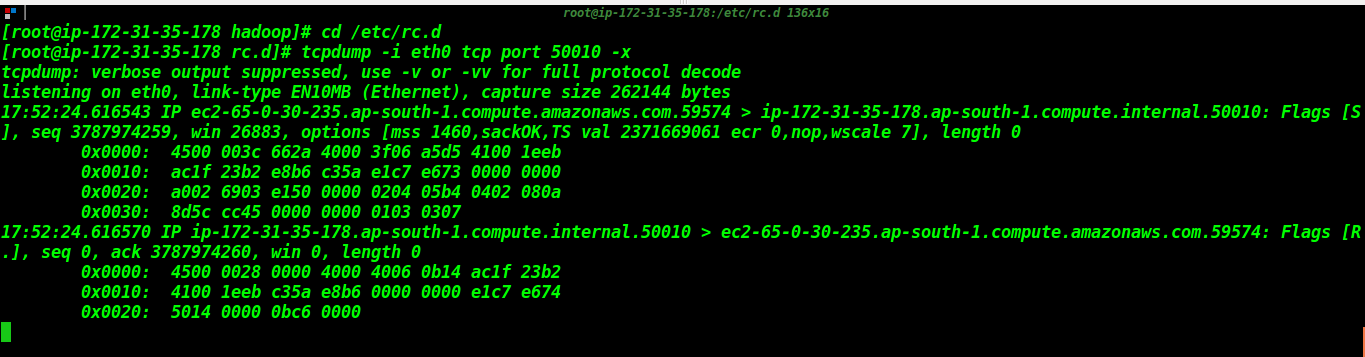
Now when we know from which node the data is being read, we will pretend and create an environment like the node has been crashed from which the data was being read by close everything running using ctrl + c and simply switching that system off.

We kept monitoring the other systems and also continued reading the large file uploaded by us. We were surprised to see that we didn't experience any problem even for a milli second after the system crashed and hadoop seamlessly switched to other datanode or replica to continue serving the file being read by the user. We started getting data packets on our other node as shown in screenshots below:

This is how hadoop works at the backend. It's so quick and reliable for big data with it's replicas and data blocks. It can be trusted and is being trusted by corporates in their business with it's powerful algorithms working at it's backend. I hope you liked this demonstration about how hadoop works if the data node gets crashed from which the file was being read by the user.
Enjoyed this post?
Get AI + DevOps insights delivered to your inbox. No spam, unsubscribe anytime.